Dartmouth Daily Updates Classifier
COSC174
Milestone Final Write-up
Machine
Learning with Prof. Lorenzo Torresani
Rui wang, Tianxing Li, and Jing Li
Mar
8th, 2013
1.Introduction
'Dartmouth Daily Updates (D2U)Æ is a
daily email news digest sent to faculty, staff and students at 1am, which
provides us information about what is happening on campus, such as academic
seminars, art performances, sports games, traditional events, etc. However, the
email digest is usually very long and the information it contains is not
categorized to satisfy peopleÆs different interest. Imagine you are about to go
to bed at 1am, or you quickly check your email before starting your work in the
early morning, we usually delete it without paying any attention.
Unfortunately, we miss a lot of useful information.
Based on this, we developed our goal
which is to provide a dreaming application that classifies the emails to a
predefined set of generic class, such as talks, arts, academic, medical, free
food, etc., for people to get their interested information at their first
sight.
Since most of the events within D2U are
written as short text messages, which do not provide sufficient word
occurrences, traditional classification methods, such as 'Bag-of-words', could
not classify the information precisely and efficiently. To solve this
limitation, our novel classification method not only gathers the information
from the text messages, but also extracts additional background information including
time of the events, sender profile and URL that belong to the college life
scenarios.
2.
Method and Experiment
2.1 Data Acquisition
In this step, we wrote a Python script to
automatically scan the websiteÆs link that belongs to each event from D2U
database. The content within the websites was extracted and used as our raw
data.
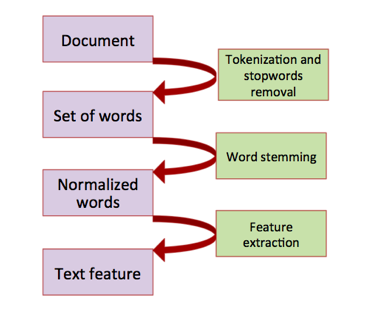
Figure
1: The detailed steps of our data preprocessing.
2.2 Data preprocessing
The purpose of this step was to
preprocess text and represent each document as a feature vector. In details,
for each event from D2U email, we did the following subtasks:
1.
A word
splitter was used to separate the whole text into individual words. For example, the input ōDartmouth Daily Updates
Classifierö was spitted into four words, ōDartmouthö, ōDailyö, ōUpdatesö, and
ōClassifierö, separately.
2.
Common words
that are usually useless for text classification were removed. In this case, words such as ōaö, ōtheö, ōIö, ōheö,
ōsheö, ōisö, ōareö, etc., were removed.
3.
Porter
stemmer was used to normalize the words that were derived from the same root. For instance, by doing word stemming, both of
ōclassifyingö and ōclassifiedö were changed to ōclassifyö.
4.
Feature
extraction. In our project, each
word was used as a feature, and TF-IDF was further calculated as the value of
the features.
2.3
Ground truth labeling
Our dataset covers the latest 90 daysÆ
emails from D2U, which has a total size of 803 events. We then manually labeled
all those events using following 15 different categories. The pre-defined
labels were mapped into two groups, with differently represented forms (Group
1) and eventsÆ contents (Group 2). The labels are shown below:
Group 1 ="1 TALK 2 MEETING 3 PERFORM 4 EXHIBITION 5
GAME".
Group 2 ="11 ART 12 HOUSING 13 JOBS 14 MED 15 SPORTS 16
IT 17 ACADEMIC 18 PARTY 19 FREE_FOOD 0 OTHER".
However, we reduced the labels to only 5
of them since there were insufficient emails used for training under some of
the labels.
2.4.1 Single label classification
For
single label classification, we used external code from http://www.csie.ntu.edu.tw/~cjlin/libsvm/Ā and http://www.csie.ntu.edu.tw/~cjlin/liblinear/
The classifier we tried are shown as follow:
L2-regularized
logistic regression (primal)
L2-regularized
L2-loss support vector classification (dual)
L2-regularized
L1-loss support vector classification (dual)
Support vector
classification by Crammer and Singer
L1-regularized
L2-loss support vector classification
L2-regularized
logistic regression (dual)
SVM
2.4.2
Previous method on multi-label classification
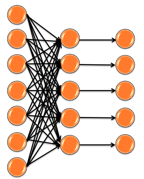
Figure 2: Previous multi-label classification method
The previous
multi-label classification was a combination of single-label classifiers. As
the figure shown above, we trained each single label classifier to achieve a
single output, and we simply combine these outputs together for multi-label
results.
2.4.3
New method on multi-label classification
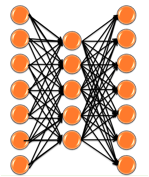
Figure 3: New multi-label classification method
Since our
previous multi-label classification method did not get reasonable results on
the milestone, we changed to a new multi-label classification method, which is
called Artificial Neural Network (ANN). As shown in the diagram above, a
number of hidden nodes were set between input and output, and the hidden nodes
were iteratively updated during our training process. Below, shows the detailed
algorithm explanation.
Mathematically,
the goal of this method is to minimize the following error function, where c
are the output labels, Y is the true positive and Y bar is the true negative:
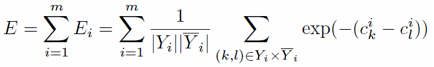
During the
training process, the following parameters are iteratively updated until their
convergence (7):
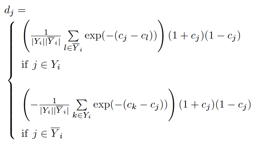
![]()
![]()
Where ah is input h-th features,
bs is s-th hidden node, cj
is j-th
output label, vhs is the weights between h-th feature
node and s-th hidden
node, wsj
is the weights between s-th hidden node and j-th output node.
2.5 Testing
To validate and visualize our results, we
used 5-cross validation and calculated both precision and recall values on test
set.
Mathematically,
we used the weights between feature nodes and hidden nodes and the weights
between hidden nodes and output nodes to predict the output labels as follows
(7):
![]()
![]()
![]()
![]()
![]()
Where netbs
is the input to the s-th
hidden unit, bs is the output of the s-th hidden
unit, netcj is the input to
the j-th output
unit, and cj
is the output label associate to jth label.
3. Results and Discussion
3.1
Performance of single label classification
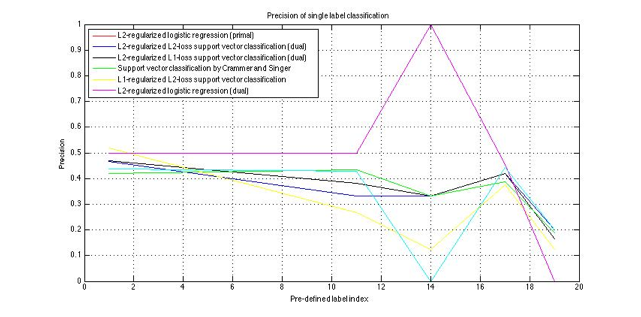
Figure 4: Precision of single label classification
algorithms
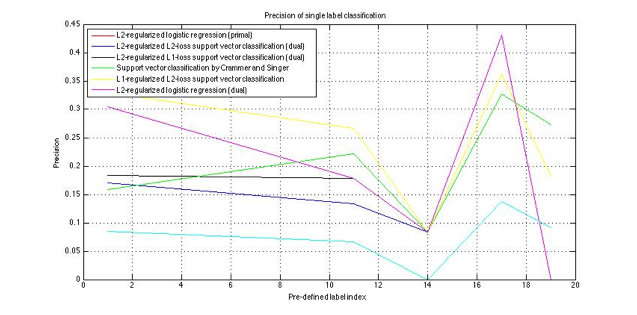
Figure 5: Recall of single label classification
algorithms
Based on our result, different
classifiers have better/worse performance on different labels. Classifiers
achieved better performance on labels- TALK, ART and ACADEMIC than the rest 3
labels. After further investigation on our training set, we found there were
more documents with one or more labels under these three categories, which
indicates that the size of our training set has a big impact on the
classification performance. Besides, some algorithm, for instance,
L2-regularized logistic regression, over-fitted on 14th label and
under-fitted on 19th label.
Ā
3.2 Performance of old multi-label classification
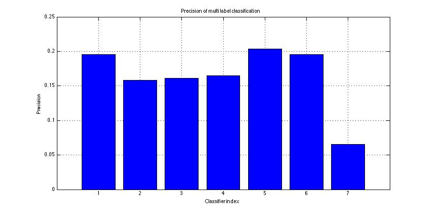
Figure 6: Precision of old multi label classification
algorithms
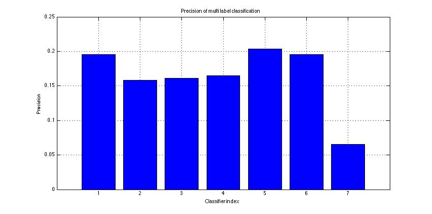
Figure 7: Precision of old multi label classification
algorithms
Since our multi-label
classification method was built on a set of classifiers, the performance of the
multi-label classification had a huge correlation with the performance of
single-label classification method it was based on. Due to our poor results of
the single label classifiers, the result of our previous multi label
classification method was therefore poor.
3.3
Performance of new multi-label classification (ANN)
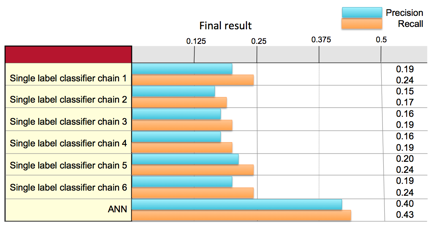
Figure 8: Precision and recall of new multi label
classification algorithm and other single label classification algorithms
As you can see in the figure above, our
new method made a much better performance compared with our previous method.
The reason of the better performance was due to the ANN considers the
relationships between each label, so that the weights between labels in the
same layer were updated together; however, our previous multi label
classification method, which independently calculated the results of each
label, therefore did not achieve proper results in our experiments. Besides, this
comparison was using the same dataset when doing both multi label
classification methods. But we can also predict, by including more training
data to our classification model, the performance of our new multi-label
classification could also be improved.
4 Conclusions
We tested 2 main methods for multi-label
classification: problem transformation and algorithm adaption. In problem
transformation method, each document has been used L times to train M binary
classifiers, where L is the number of document s labels and M is the number ofion method, which independently calculated the results of
each label, therefore did not achieve proper results in our experiments.
Besides, this comparison was using the same dataset when doing both multi label
classification methods. But we can also predict, by including more training
data to our classification model, the performance of our new multi-label
classification could also be improved.
4 Conclusions
We tested 2 main methods for multi-label
classification: problem transformation and algorithm adaption. In problem
transformation method, each document has been used L times to train M binary
classifiers, where L is the number of document s labels and M is the number of
predefined labels. Each document will go through a classifier chain during
which the labels will be generated. In algorithm adaption method, we
implemented an artificial neural network with M output units associate to the
predefined labels. Our results show that the later method performs twice as
better as the problem transformation method. We believe this difference of
performance is due to transformation method does not take the correlation of
different labels into consideration, which may provide clues for the co-existing
of different labels.
As we have stated in the milestone,
limited data size is a big issue for us. We have to eliminate many labels due
to there are only a small number of documents have these labels. In future
work, the performance can be further improved by adding more training data,
expanding feature space using document meta-data and transform certain text
features to entities.
5 Reference
[1]Bharath Sriram,
David Fuhry, Engin Demir, Hakan Ferhatosmanoglu,
Murat Demirbas. Short Text Classification in Twitter to Improve Information
Filtering.
[2]Xia Hu, Nan Sun, Chao Zhang, Tat-Seng
Chua. Exploiting
Internal and External Semantics for the Clustering of Short Texts Using World
Knowledge.
[3]Sarah
Zelikovitz. Transductive LSI for Short Text Classi’¼ücation
Problems.
[4]Barbara
Rosario. Latent Semantic
Indexing: An overview.
[5]Deerwester, Dumais, Furnas, Lanouauer, and Harshman. Indexing by latent semantic
analysis.
[6]David
M. Blei, Andrew Y. Ng, Michael I. Jordan. Latent Dirichlet Allocation.
[7] Min-Ling
Zhang and Zhi-Hua Zhou, Multi-Label Neural Networks
with Applications to Functional Genomics and Text Categorization, IEEE 2006